Even the simplest distributed system – yes, even integrating against a single API – can pose significant challenges (more than 80% of solutions that SMEs have). Mind-blowing, right!?
Microservices RED Flags - Designing Microservices the Right Way
This article is part of the serie: distributed-systems
Posted Feb 26, 2024
By Balázs HIDEGHÉTY
4 min reading time

Remember, business goals are rarely about having a top-notch system!
Finally, we have arrived at the point where we can discuss the pinnacle of modern software architecture: microservices.
When it comes to designing a software system, it’s not easy. Designing microservices is even harder. And even if you do it right, there are situations where you will run into issues.
This is why I always suggest that before contemplating Microservices, one should always consider scaling up. Here’s my article on LinkedIn about 10 scaling-up possibilities before considering microservices - also available here.
Today’s lesson and the summary are based on these two great talks:
- Microservices and Rules Engines – a Blast from the Past - Udi Dahan
- Avoiding Microservice Megadisasters - Jimmy Bogard
Let’s dive into the nuances and challenges of microservices…
Consider this summary article as a concise way to reinforce the main message: one should always consider scaling up first.
Business first
Remember, business goals are rarely about having a top-notch system!
We should aim for a decent one that’s easy to maintain, extend, and scale.
The best example of how a simple approach can outperform a full-fledged system is demonstrated in a Microservices-related conference by Jimmy Bogard.
To achieve higher business goals, like increasing checkouts and paying customers, he opted to disable certain input validations (such as those on credit card numbers) and avoid blocking or frustrating users during checkout. Thus addressing any issues later via an in-person phone call proved more advantageous for the company than insisting on a top-notch form or system upfront, potentially resulting in losing clients.
Microservices RED FLAGS
If you notice any of these signs, then you’re approaching microservices the wrong way:
- 1️⃣ Unclear data ownership.
- 2️⃣ Shared data store (either directly through the database, indirectly via a REST layer on the database, or through other workarounds).
- 3️⃣ Excessive service dependencies - Cascading API calls beyond the gateway create complex dependencies and increase the risk of API hell and distributed deadlocks.
- 4️⃣ Replication via messaging - Volatile business logic data is duplicated through pub-sub mechanisms, indicating incorrect service boundaries and unclear service responsibilities.
- 5️⃣ Overly granular services
What to know when designing microservices
It’s all about mindset. To do it right, we need to understand:
- The correct definition of a service, considering both their hosting and data aspects.
- The truth about coupling.
- The importance of service boundaries and data ownership.
- There are situations where microservices do not fit well (but that aspect is manageable as well).
All these details are provided in the main video.
Where microservices come short
However, as your business needs become more intricate, such as with Rules Engines, you may encounter challenges with encapsulation.
What are those business use cases? Here are some examples:
- Search (engine)
- Pricing (engine)
- Fraud detection (engine)
In these instances, you require data from multiple services, and the temptation might be to simply send that data across! But please, refrain from doing so!
Microservices - Major takeaways
There are the major takeaways:
- coupling is a part of real life, so it is part of the code
- we can’t remove top-to-bottom coupling, but we can remove side-by-side coupling (using micro frontends and UI composition)
- definition of: systems, services, unit of deployment…
- services own their data, they should not share data (to other systems) that’s volatile
These are services:
- product information
- price information
- inventory levels
But these aren’t:
- search
- pricing
- fraud detection …these are composite kinds of systems…
Search is challenging; Google has set high standards, leading to unrealistic expectations for searches conducted by small teams in a matter of weeks, in contrast to Google’s search engine developed by a team of 10,000 developers.
How we solve those cross-cutting services
…which needs data from everywhere?
The bell.com case - duplicating data
Sometimes, we can do it by duplicating data relevant to the search (redundant or limited data, that can be recreated at any time).
This type of dependency inversion is what Jimmy Bogard showcased in the 2nd linked video [^2] (but please keep in mind that that design choice was given by the existing system which they tried to fix)…
…or we can do it via composing components from services
The hosting (composing) side of microservices
- We take “parts” from different services, we arrange all them together on that platform (system)
- The system does not really have its own code, all the code belong to the services.
- The system does not really own any data, the data is owned by those services.
This approach allows us to create these generic engines (systems)!
…but introducing dependencies between systems implies the need for orchestrated deployments. Consequently, tools like Kubernetes become essential for managing and coordinating the deployment of these interdependent systems efficiently.
The data side of microservices
- The system (referenced previously in the hosting section) does not own the data.
- The data is owned by the services.
- The service doesn’t share that data; it doesn’t send it out to other microservices, neither through an API call nor via a shared database.
- Even with pub-sub, ideally, you want to be sending nothing more than some identifiers.
If you start sharing data that’s volatile, such as a price or an address, that’s when you start getting into trouble. Again, the issue here is not about how you share it but the fact that you’re sharing it in the first place.
Generic engines
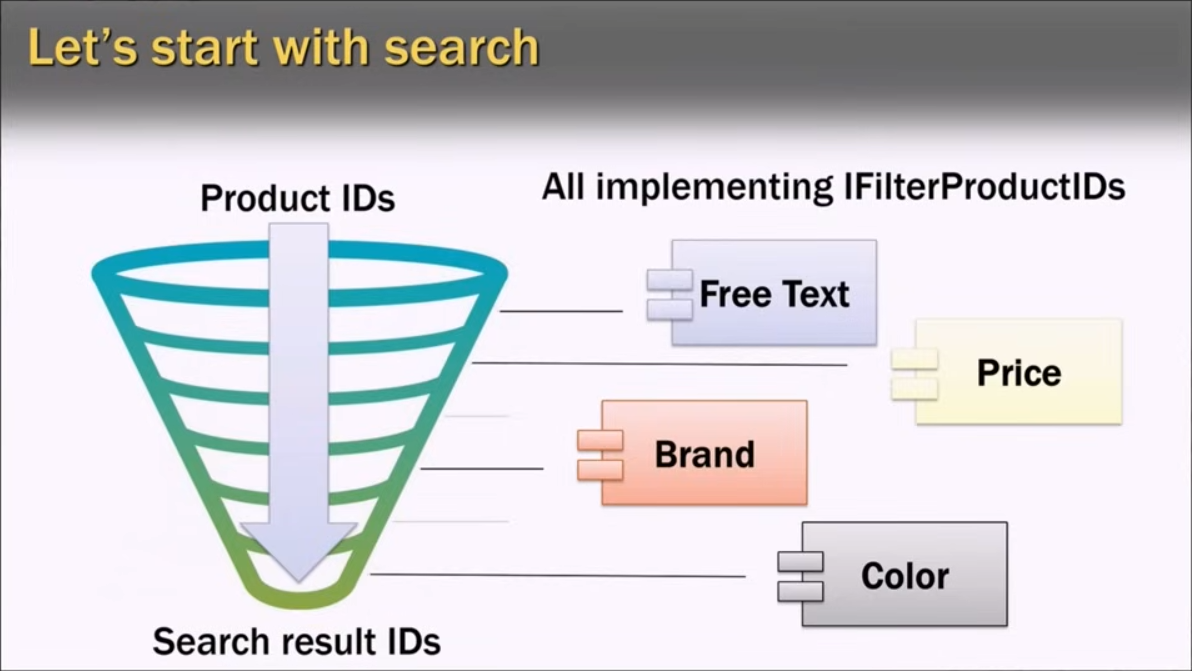
Search engine
Search is not just about free-text search.
Relevance matters as well (especially in the case of a huge amount of data).
- price
- brand
- color
- …
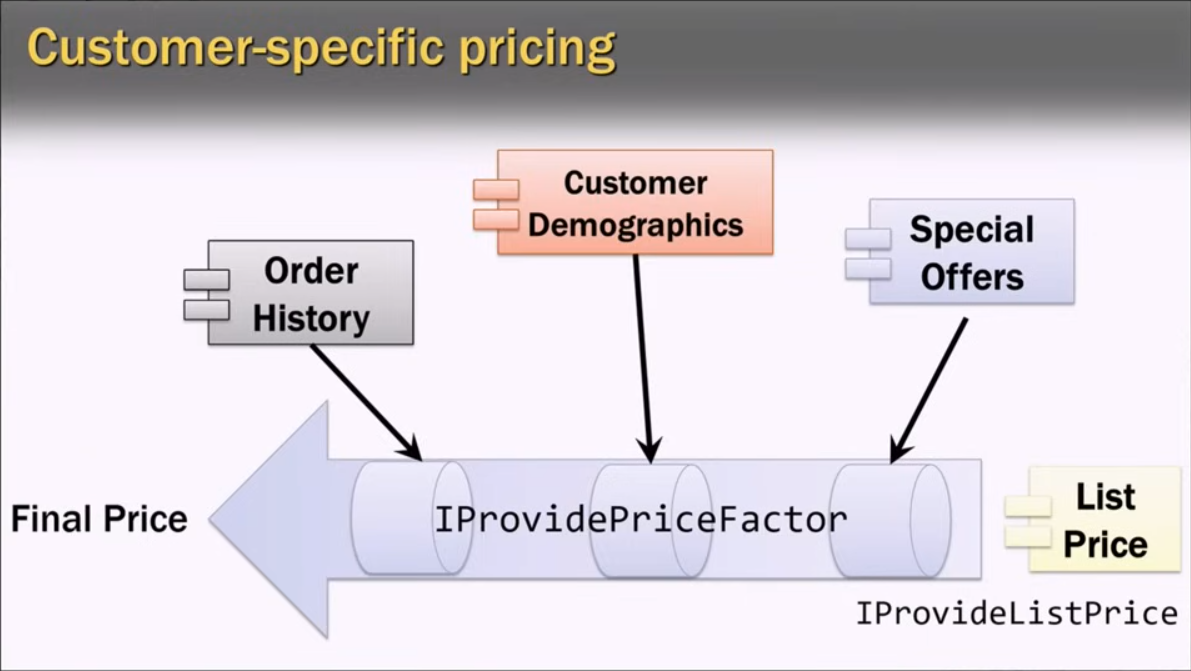
Pricing engine
Same as search, customer specific pricing and fraud detection too will need access to multiple services, we will actually need to access specific classes implementing specific interfaces from those services.
Plug’n’ Play
Assembly-scanning gives plug-n-play
At process startup, scan the runtime directory, load all assemblies, and scan types for those that implement a specific interface (IProvidePriceFactor, IProvideFraudMultiple, …).
Outro
Hopefully, with all these details, you will be able to develop your first microservice successfully and without mega-disasters…
But is that all? Well, not really. We talked about design, but there’s one challenge that still remains: managing the deployment (of physical service instances referred to previously as systems), where a single physical service instance can depend on multiple logical microservices.
📌 Make sure you and your team subscribe (follow me) on LinkedIn so you don’t miss out on the latest insights!