Even the simplest distributed system – yes, even integrating against a single API – can pose significant challenges (more than 80% of solutions that SMEs have). Mind-blowing, right!?
6 Little Lines of Fail - Everything is Distributed
This article is part of the serie: distributed-systems
Posted Feb 05, 2024
By Balázs HIDEGHÉTY
6 min reading time

In today’s tech-driven world, even the simplest-looking code can wreak havoc if not handled by seasoned experts. This’s why technical experts are not just “nice to have” for companies, but a crucial lifeline.
TimeoutException - Probably, this is one of the trickiest errors of all because, sometimes, it’s not even an error!
Today’s “lesson” is for management.
It’s short and simple.
Your company engages in distributed computing, whether it realizes it or not…
…just as your company is a tech company, whether you realize it or not (you depend on technology, you use it to fuel your business).
So you need technical experts more desperately than you’d ever admit to yourself.
Because…
FAILURE IS ALWAYS AN OPTION!
Intro
Distributed computing is not easy.
How difficult is it?
Well…
Here are six lines of code;
Nicely written;
Easy to read;
They are perfect;
– yet…
…with distributed computing, disaster awaits under the hood.
- Don’t let hidden disasters sabotage your company’s success.
- Embrace the power of technical expertise.
- Minimize failures - by ensuring that at least two pairs of eyes are always on your code (yes, two seniors are better than one).
That’s it. (That’s my message!)
Regarding the content below: I suggest to check out at least the summary to see what kind of business related decisions building a software requires - for that, scroll there via this link.
–
The linked video (and its summary) is primarily intended for developers and curious managers. Both audiences need to grasp that technical decisions are shaped by business requirements, emphasizing the crucial role of effective communication.
–
📌 So here it is: Six Little Lines of Fail - Jimmy Bogard - YouTube
6 Little Lines of Fail - Summary
5 Potential Points of Failure
The problem with the provided code is: missing failure handling
There are five potential points of failure:
- When the call to the database (order placement) fails: The system displays an error message, but it remains consistent (although no error is good after credit card information has been entered into the system)!
- When the call to Stripe fails:
- Timeout error: The payment may have been processed successfully (money withdrawn), but the user receives a timeout exception. Probably, this is one of the trickiest errors of all because, sometimes, it’s not even an error!
- On other errors: The system remains at least consistent.
- When SendGrid fails: With Stripe already succeeding and the transaction being rolled back, the user is billed for nothing. (The customer calls customer service, incurring further costs, and there is no order detail, leading to a poor user experience.)
- When RabbitMQ fails: Similar issues arise as with SendGrid (plus we already told the customer that the payment was successful).
- When the transaction fails: All the issues above occur.
So how to avoid them?
You don’t!
You can’t!
It’s not a matter of WHETHER something fails, but rather WHEN it does.
FAILURE IS ALWAYS AN OPTION!
ASSUME FAILURES, PLAN FOR THE WORST!
–
But good news;
There are 4 options for dealing with failures.
Dealing with failures (in software)
Introducing Gregor Hohpe’s insightful perspectives on handling failures…
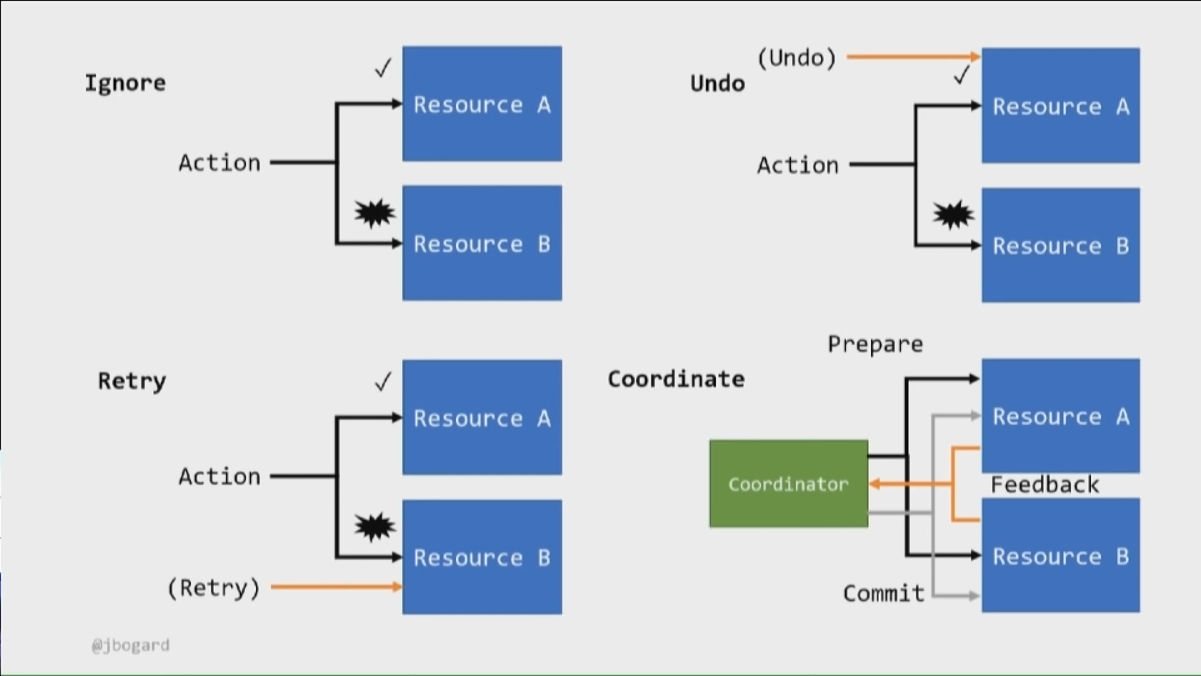
There are 4 options for dealing with failures:
- Ignore failure - For non-critical cases and non occuring failures (like logging failures aren’t critical for the business)
- Retry operation - Can it be retried? How long to retry? How to handle constant failing? Needs a retry policy!
- Undo action (compensation) for the succeeded part(s) if other parts fail (or database transaction rollback).
- Coordinate: Prepare / Commit phase - Real-life sample: buying a house via a broker - it comes with a cost (money and/or time overhead).
Which one of the four options to choose? It depends mostly on the business, but in some cases, the technical capabilities of the underlying systems might also intervene (reduce options).
Explore Gregor Hohpe’s valuable insights on handling failures through his compelling works:
- Starbucks Does Not Use Two-Phase Commit
- The Software Architect Elevator: Redefining the Architect’s Role in the Digital Enterprise: Hohpe, Gregor: 9781492077541: Amazon.com: Books
The Master Plan
For each external resource, examine possibilities and pick the best option based on business requirements!
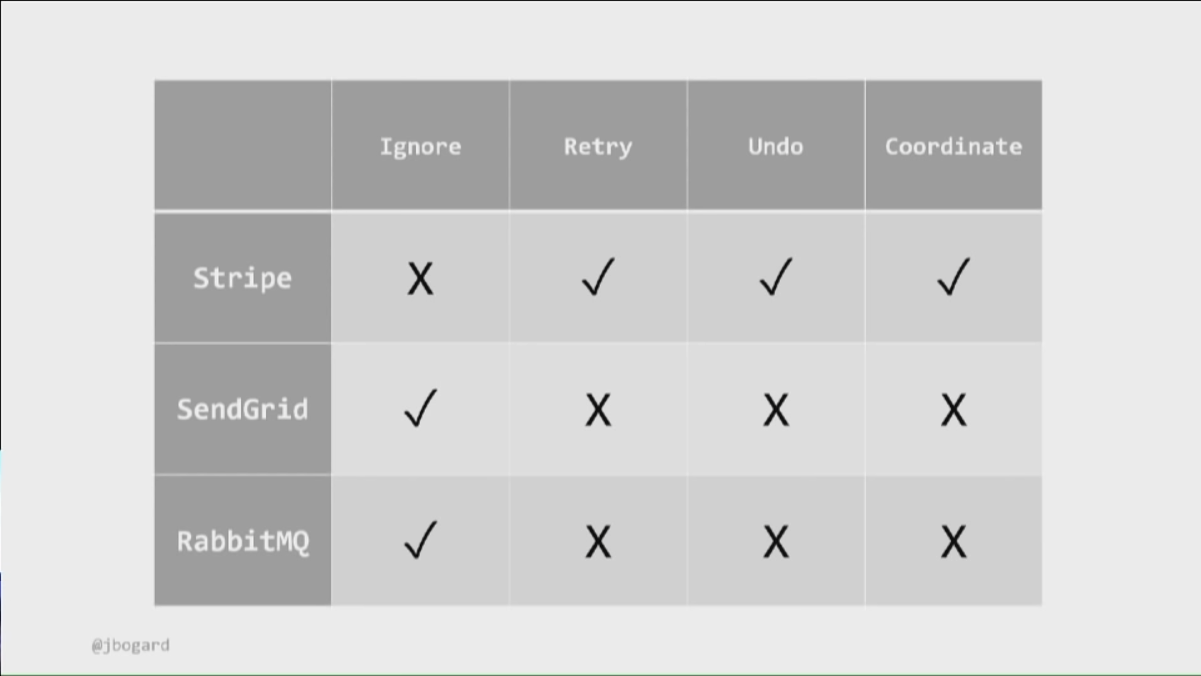
STRIPE
- Ignore - We don’t want to ignore a failed payment, we want to fulfill the order (although in real world we might ignore payment problems - like loyal client, small amount, etc.)
- Retry - We need to avoid double charging; we need idempotency! Usual cases of double charging can include: double-click, timeout issues followed by retries. Google: stripe idempotency (idempotency key or cartId)!
- Undo - Credit vs. refund which is supported by stripe! But what if refund fails? What if refund timeouts?
- Coordinate - Stripe supports 2 step payment flows (pending transaction)! Authorize and then capture. If capture fails, the Stripe UI allows to do manual retries…
SEND GRID
- Ignore - Do we want to fail the entire order process if we can’t send a “thank you for your order” email? Here ignore can be a valid option!
- Retry - Sendgrid has no idempotency. The business would like to have exactly one email sent out, but that does not work with distributed systems. So, they have to choose between 0 or 1 email, or at least one (so 1 or more) email(s)!
- Undo - NOT POSSIBLE (Google postpones email sending to allow undo - they wait 10-second before sending an email). We can do business level compensation actions: apology email and providing coupons.
- Coordinate - N/A
RabbitMQ (similar to emails)
- Ignore - Flag the order and let a background process to retry failed messages later on) - SET order.needsOrderCreatedEventRaised = true;
- Retry - Azure Service Bus has duplicate message detection within a given time period; others have the concept of retry. However, RabbitMQ does not, so here we need to know how consumers react to duplicate messages. We need to have control there (on the consumer side) or choose another option to deal with the failure.
- Undo - N/A - We can’t unsend the message! Compensating message would be weird! From a business perspective an undo of the order is an option.
- Coordinate - N/A
Breaking The Process Coupling
We can’t encode all these options directly into the main code!
…too much branching leads to unmaintainable code!
So we need a different approach!
Can we avoid exceptions by breaking the process coupling? The answer is: yes, we can! But how is something that the business has to define.
Can we avoid exceptions by breaking the process coupling? The answer is: yes, we can! However, there are many details that the business needs to define.
The Business Part
We need to ask:
- Do we have to execute these steps now, or can we execute them in the future?
- Is there a specific order in which the steps should be executed?
Payment (STRIPE)
Businesses with finite amount of resources (movie tickets bound to a seat, reservation timer) might need to charge immediately, while Amazon with infinite stocks might allow to charge later (in this case we can utilize a background process for payment and even do easily retries for failed charging).
Notification (SENDGRID)
When to email the user: after placing the order or when the payment goes through? Is it okay to delay the order notification if the payment fails (knowing that we’ll try again)? What if the user thinks the order failed and buys elsewhere? How about sending separate emails for a successful order and payment?
There’s another business decision here regarding retries (mentioned in the previous chapter): In the event of issues, we can’t ensure that exactly one email is sent out. We can have either 0 or 1 email sent (e.g., it’s acceptable if the user does not receive an email at all), or we can ensure at least 1 email being sent (e.g., it’s acceptable if the user occasionally receives duplicate emails).
Fulfilling the order / Order placed event (RABBITMQ)
After placing an order, we inform others to fulfill it.
Have you considered this? Despite having consistent data in our database, clarity only emerges when warehouse personnel check. This is especially true with finite resources, particularly when selling the last items. Only by checking the store can we be sure if we’re able to fulfill the order. Consider this as another kind of “eventual” consistency, as issues like loss, theft, damage, direct sale, or processes outside the usual protocol can lead to discrepancies between the real stock count and the database.
IMPORTANT: In messaging systems, when dispatching messages as a part of an atomic operation, it is important to understand and implement the outbox pattern.
The Technical Part
Modern eCommerce uses background processes to fulfill an order (higher degree of success)!
For this, we can leverage workflows. Here are some workflow patterns to consider:
- Routing Slip: Linear flow.
- Saga Pattern (e.g., booking a holiday with car, hotel, and flight): With compensation, useful for simple scenarios where each step can be executed individually.
- Process Manager Pattern: Orchestration, command-based (order matters), or choreography, event-based.
There’s another kind of Saga definition that closely aligns with the Process Manager pattern. Check out Saga pattern - Azure Design Patterns | Microsoft Learn for insights into orchestration and choreography differences, along with their pros and cons.
Conclusion
In the dynamic realm of distributed computing, technical expertise is essential to navigate potential pitfalls, as highlighted by the elusive TimeoutException.
This article and the linked video underscores the inevitability of failures and introduces strategies to address them, emphasizing the need for a tailored approach aligning with business requirements and technical capabilities. It stresses the importance of breaking process coupling and concludes by advocating for the use of workflow patterns to efficiently orchestrate complex processes, highlighting the delicate interplay between business and technology in the digital landscape.
📌 Make sure you and your team subscribe (follow me) on LinkedIn so you don’t miss out on the latest insights!